GSD
Caching Strategies: Everything You Need to Know
Posted by Abhishek Kothari on October 18, 2023
Over the years, the size of web applications has grown considerably larger with the arrival of multimedia and rich graphics. This has been made possible with the use of numerous supporting libraries and stylesheets.
Modern user interfaces not only load large amounts of resources but also load large amounts of data, including data from API-based CMS systems. Downloading these resources and data each time is time-consuming and also costly.
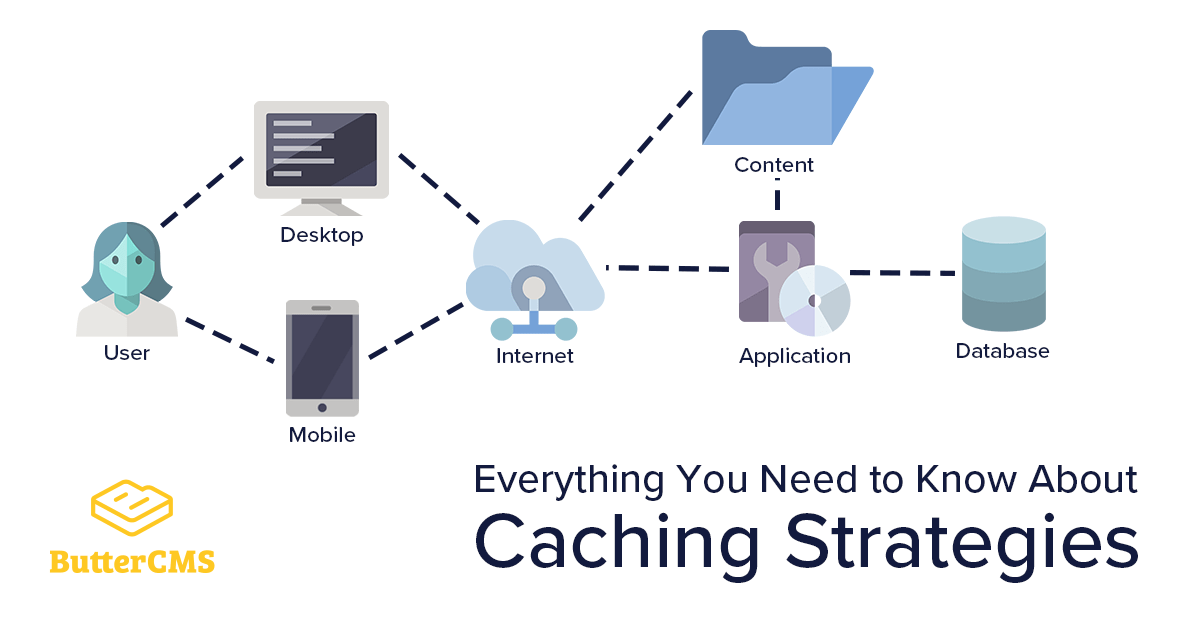
This is precisely where web and API caching strategies come to the rescue. Caching helps in reducing these calls while maintaining the quality of output.
Table of contents
Caching 101: A quick overview
Caching means to store resources or data once retrieved as cache. Once stored, the browser/API client can get the data from the cache. This means the server will not have to process or retrieve the data repeatedly. Consequently, it results in a reduced load on the server.
Caching does seem like a simple concept - Store the data and retrieve it from the cache when needed again. However, it can become complex when implemented. Caching strategies should be understood and applied carefully. In this article, we will try to capture all you need to know about caching and various caching strategies.
Different caching strategies
Now that we have an understanding of what caching is, let us understand the various caching strategies that exist. Each resource being cached needs to have the right caching strategies associated with it to ensure it does not disrupt the functionality of the application. Further in this article, we will discuss the different variations and go deeper into them to explain how each of the caching strategies is unique in its own way.

Browser level/Local caching
Browser level caching means to store the resources and API responses at the user level. This enables the web application to load considerably faster compared to a fresh load. Browser level caching utilizes the browser’s local data store and disk space to save resources. The browser also maintains an index of these resources along with their expiry time. The expiry time is the duration until the cache is considered valid. Depending on how often you change your resources, these expiry times may differ.
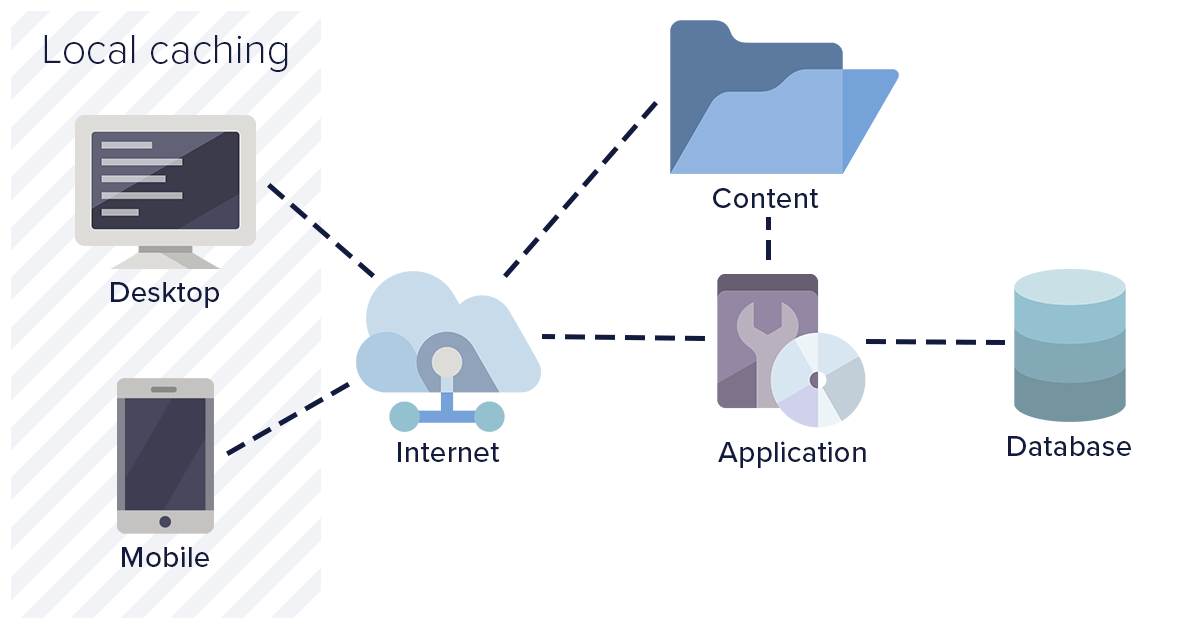
The browser is capable of caching not only JS or CSS files, but also images, API responses, and full web pages depending on how the website you visit is configured.
Benefits
- Browser level cache consumes space only on a user’s system
- Browser level cache helps in avoiding a full round trip to the server and back for getting resources
- Results in quick loading of the web page
- Reduced API calls to the server consequently reduce server traffic
Drawbacks
- If expiry time is configured too long, it could load stale files and the application might not function correctly
- If the resources are too heavy, much of a client’s disk space could get consumed
- We do not have control over the cache
Object level caching
Templating of web pages has become a common approach towards web development today. The object level caching strategy involves the caching of pre-processed pages at the server level along with the data. This helps in preventing frequent database calls as well as page processing calls. An object basically can be any resource, data, or web page. Object level caching is more beneficial when the web application is expecting more new users on a regular basis.
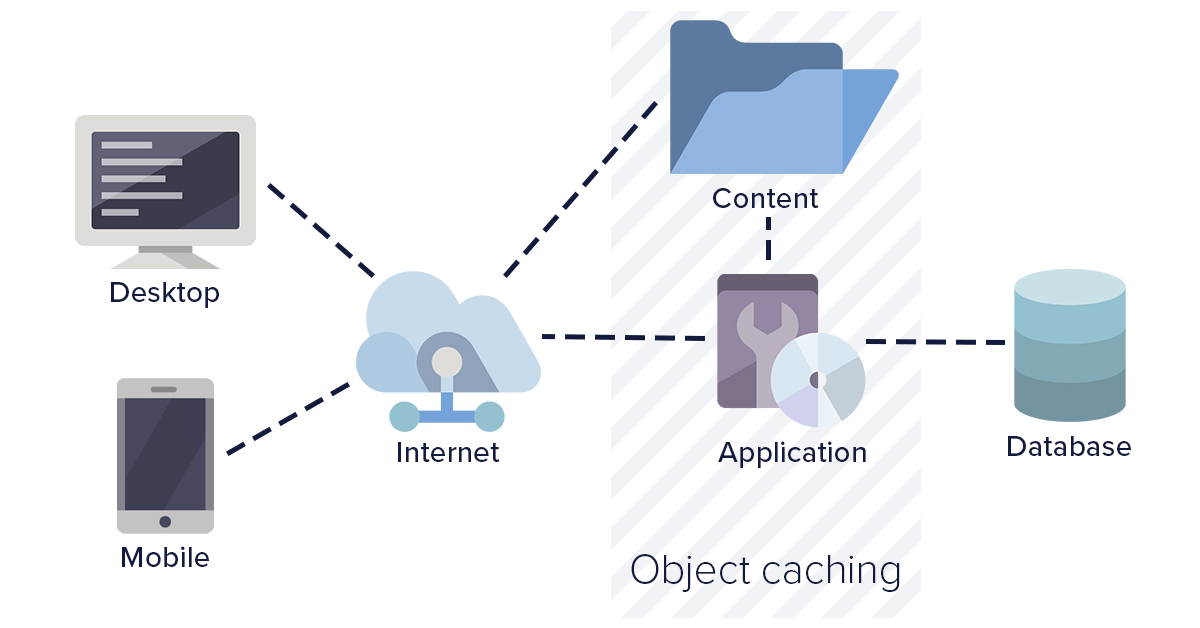
Benefits
- Common cache for all users helps in ensuring the right content delivery
- Cache expiry is controlled by the server
- Results in the optimization of database calls too
Drawbacks
- Occupies server disk space
- Requires a shared disk or cache duplication in case of load-balanced multiple servers
Network level caching
Network level caching is a modern caching methodology where your intermediate HTTP web server and routers are configured to cache the API calls and resources. In this method of caching, we configure the network layer to hold the responses and resources for corresponding URLs. This type of caching works strictly based on URL. The network layer can be configured to use or ignore query parameters for the URLs as needed by your application.
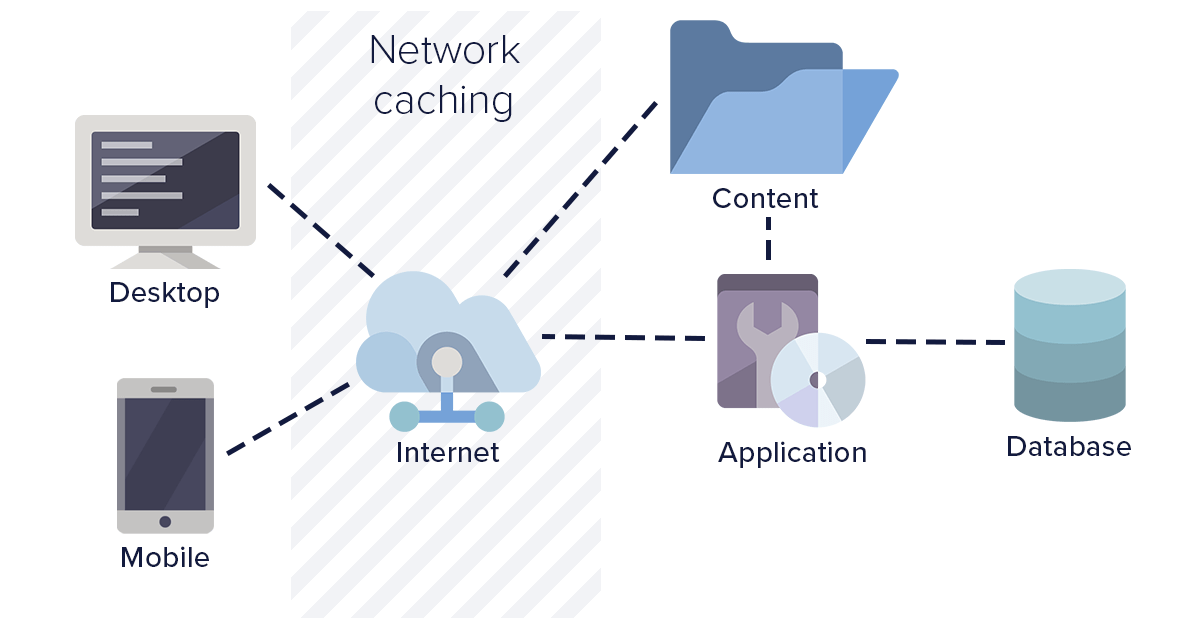
Network layer caching improves the overall performance by completely avoiding the calls for a response. Thus, it results in better performance compared to object level caching. In certain setups, the users would be hitting a regional network layer closer to their location. This can improve the response time considerably as a roundtrip to the servers would be saved.
Benefits
- Common cache irrespective of servers resulting in more accurate rendering
- Reduced hits on the application servers due to network layer caching
- Faster response times in a regional network layer setup
Drawbacks
- Requires a durable network layer with sufficient disk space to hold the cache
- The traffic and bandwidth requirement at network layers increases
Third-party caching using cache stores
This is the best caching method in use at present. Third-party caching involves routing resource-intensive calls through third-party cache providers. These cache providers are then responsible to hold, manage, and clean the cache as needed. Moreover, the cache stores also provide better transparency into what the current cache is holding and allows you to clear the cache when desired.
With third-party caching, you can also make sure that the same cache is served around the world irrespective of country or region. Thus, they also improve the website performance in turn by cascading data to locations closer to the user.
Benefits
- Complete responsibility of the cache is handled by the third party
- Gives you full control over the cache while ensuring that any changes are replicated throughout the world
- Reduces hits on web application servers
- Faster website performance due to durable high speed caching servers
Drawbacks
- Costlier compared to the previous cache strategies discussed
Advantages of caching
From the above, we understand that caching is surely a must for the majority of web applications. Below are some high-level advantages of implementing caching:
- Lower hits or load on web application servers
- Better website performance and load times
- Higher SEO ranking due to optimized performance
- Reduced data exchange with browser-based caching resulting in optimum consumption of internet data
- Faster execution of actions due to API caching
To get the right benefits from each caching mechanism, we need to understand the concepts associated with it in depth. These concepts are discussed further in the next section.
Importance of cache expiry
A cache is a store of files that were processed in the past and will be used in the future. These files may not remain the same throughout their lifetime. There could be scenarios where the file might get changed. In such cases, cache expiry becomes important.
Cache expiry is the time before which the cache is considered valid. When the request for files is sent to the server, the server returns the relevant headers to specify the expiry time for the respective file. The caching engine (browser, third-party, or network layer) maintains this expiry for each file and takes care of refreshing it on time. Consequently, the stale cache issue will cease to exist. When analyzing the impact of different caching strategies, it is important to ensure that there is an option for configuring a custom cache expiry.
Drawbacks of extreme caching
Caching, although beneficial, still needs to be done carefully. You need to understand the files that are important to be cached. At the same time, you also need to carefully decide on the expiry time for the cache. Extreme caching is the situation where the web application servers cache every possible file with a high expiration time.
Extreme caching could end up resulting in improper performance of the web application. Stale JS or CSS files or data from API calls could result in unexpected behavior, too. Hence, it is important to carefully cache the resources and at the same time refresh the cache whenever updates are being made. The next section helps you carefully strategize caching for each resource.
Choosing the right caching strategy for your app
Caching static resources against caching API calls requires two different caching strategies. Each strategy focuses on caching different types of data. Before strategizing for the same, you need to segregate the resources and API calls into the categories below:
- Static resources: JS, CSS, Font files, and images that change very rarely
- Master data API calls: API calls that provide data that does not change often
- Other resources and API calls: These are files and APIs that contain dynamic content and needs to be retrieved fresh almost every time
The segregation of resources and API calls will help in finalizing the approach to be followed for each. Then, try to organize the static resources into a separate folder to treat them differently. Now, let us try to understand the methods to be followed for each.
Static resources
The lifetime of static resources is normally high. These resources generally include the libraries and files that are brought in from a third party. For instance, this includes Bootstrap, JQuery, Google Fonts, Font Awesome, and others. These files should be cached for longer with expiration times ranging from 1 month to 3 months. The majority of people prefer to use a third-party CDN to host these libraries. However, it is not advisable to do so.
Caching of static resources will reduce the resource calls to the server considerably. These files can be cached using web browser caching. The browser can hold and manage the lifetime of these scripts. Thus, when your web application URL is entered, the browser checks all the requests that the web page makes. Based on the available cache, it pulls out the files from the disk cache.
The caching of static resources can combine browser caching and third-party caching for the best web application performance. This ensures that even for first-time caching for a new user, the web application is rarely hit.
Master data API calls with an API-first CMS
API calls caching is an interesting development that has been done over the past few years. However, caching API calls is still a tricky thing to do. Using a matured platform to cache such API calls is certainly better.
An API-first CMS like ButterCMS allows you to cache your API calls for various entities like posts, testimonials, list of services, and others. API calls caching allows faster response times for the APIs which might otherwise take 1-2 seconds if the data is too large.
With global caching, ButterCMS could deliver data for API calls quickly with less load on the server. Consequently, it results in better performance and increased satisfaction for you as a client. With CMS platforms, you can leave the complete caching responsibility to the API provider. Thus, it not only reduces your development time but also gives better quality output.
Other resources and API calls
These are the final set of resources that refresh more often and might need frequent cache cleaning to show the right data. Hence, the general advice for such resources is to ensure that it does not get cached at the user or server level. Any caching of dynamic data could impact the sanity of data visualized on the screen or consumed by a service.
Conclusion
Based on the detailed discussion above, we can summarize that caching surely is a must-do activity for every web application owner. With caching, you get numerous benefits which in turn lead to a satisfactory visitor experience. However, choosing the right one or mixing all caching strategies proportionally is a crucial activity and must be done with proper knowledge.
With the right strategy and resources, you can definitely make your web application faster and optimized for use. For more information about optimizing the performance of your web application, check out our Beginner's Guide to Front-End Performance.
ButterCMS is the #1 rated Headless CMS












Related articles
Don’t miss a single post
Get our latest articles, stay updated!
Abhishek is a software solution architect with 6+ years of experience in the industry. He has had opportunities to build and architect numerous small to large web applications and platforms leveraging various Cloud services and platforms. He also really enjoys sharing knowledge with the community by writing blogs, conducting training and building engaging courses.