GSD
When to Use NoSQL: A Guide for Beginners
Posted by Alex Williams on October 12, 2023
This article will explore the basics of when to use NoSQL over RDBMSs. We'll frame the discussion using several key use cases including headless CMS and eCommerce.
Organizing data at volume in order to manage sophisticated communication and transaction problem domains, unsurprisingly, gets very complicated.
Databases are the specialist tools that developers, data scientists, and project managers use for this.
Databases structure information according to function and form. According to the type that you use, more or less stress will be put on certain structural aspects.
Note that this is a beginner’s guide so it won’t cover greater nuances, such as blooming out of NoSQL database types that are actually hybrids between relational and non-relational (on SQL’s side of the fence: PostgreSQL is another example).
Table of contents
SQL Dislikes Varied Data
SQL, or relational or RDBMS (relational database management system), databases operate like Excel spreadsheets—information is assorted in a tabular format and different datasets and tables relate to one another in the typical way that this format allows.
For RDBMS, querying—ie. asking your database questions in order to retrieve pertinent answers—is carried out via the Structured Query Language (SQL): It’s a union between rigid tabular database schemas containing interrelated entities and properties, and a richly regimented query language adept at managing that structured data.

SQL is great for rich and structured querying, for instance, select * from customer_data pools all of your customer data from the customer_data table. Imagine this same schema used for banking transactions that answer questions based on tables...For this reason, SQL is the basis of the financial sector: Extreme integrity, consistency, and speed when it comes to transactional, table-based structured querying.
Notice the word ‘structured’.
Cons of Using SQL with Varied Data
- Scalability is much harder — Big networking goliaths like Amazon and Instagram, as well as small app startups, are constantly releasing updates, scaling up new functionalities and integrations, plus adding security patches to shore up their inevitable database vulnerabilities. Coordinating their operations would be massively inefficient monetarily and timewise without NoSQL’s flexible schema-less model.
- Massive volume data is naturally diverse — i.e. interrelationships become harder to rigidly pin. RDBMS databases struggle to manage this type of evolution, especially when rapid, as it wants to force all data types under a normalized schema of tables. However, data variability naturally occurs as a function of growing data silos.
SQL Evolves Both Slowly and Painfully
To harp on further about varied data, let’s focus on the evolutionary side of things—specifically, data expansion.
Firstly, data silos are data repositories, each managed by a department operating independently from others in the organization. In the event of more than one silo incorporating the same data, data versions and relationships between silos become precarious to model.
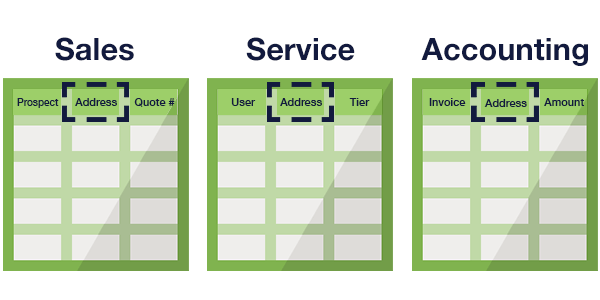
It’s hard to change relationships and tables. While SQL performs very well with thoroughly structured data, changing or altering that underlying schema as it grows is hard.
Cons of Using SQL with Evolving Data
- As data grows, SQL slows. Updates more commonly require complete downtime periods to accomplish. But with the exponential growth of data such as the 70% increase in internet use in 2020 alone, that diversity is a given.
- NoSQL wins because agile developers naturally desire a database that can naturally and easily keep pace. There is no need to repeat the exact same number of columns for every entity or entry. Adding new columns is simple, whereas it's grueling for SQL. This is because NoSQL contains columnar database types. It’s built-in.
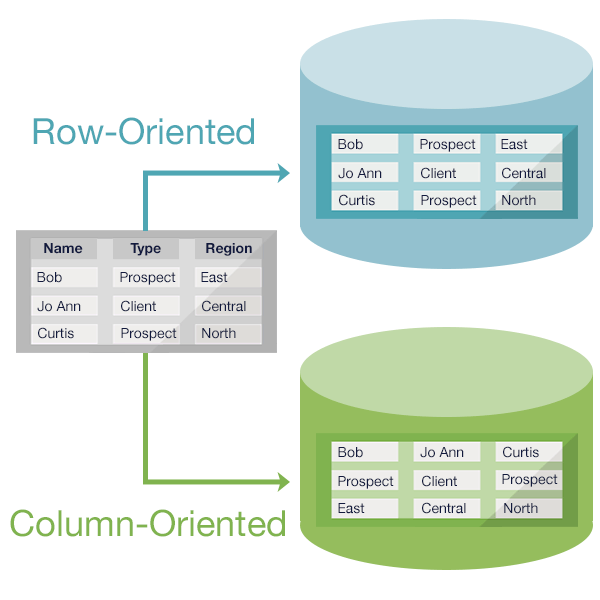
Add an entry containing only one field, or all the possible column fields. With the column-oriented NoSQL model, you’re free to add, delete, and modify data ad hoc.
A Deeper Look at Infrastructure: SQL Depends On ACID Properties
The ACID database properties are Atomicity, Consistency, Isolation, and Durability. These properties aren’t flexible.
The overview of each below should illustrate why RDBMSs’ normalized, ‘single point of truth’ approach makes it exceedingly suited for handling something like financial transactions or time-efficient bookkeeping. The ‘CAP theorem’ is also relevant to the ACID context, so will be touched on here.
- Atomicity — A binary design. If your query produces a statement error, it voids the action altogether and the transaction returns to the start.
- Consistency — All predefined protocols must also be met, in order for the transaction to succeed. This must be fully accomplished.
- Isolation — All incomplete transactions, even if midway through being completed, are isolated from new transactions. And each transaction runs independently.
- Durability — The preservation of all transactions that have committed themselves to the database. This is ensured via transaction logs and backups.
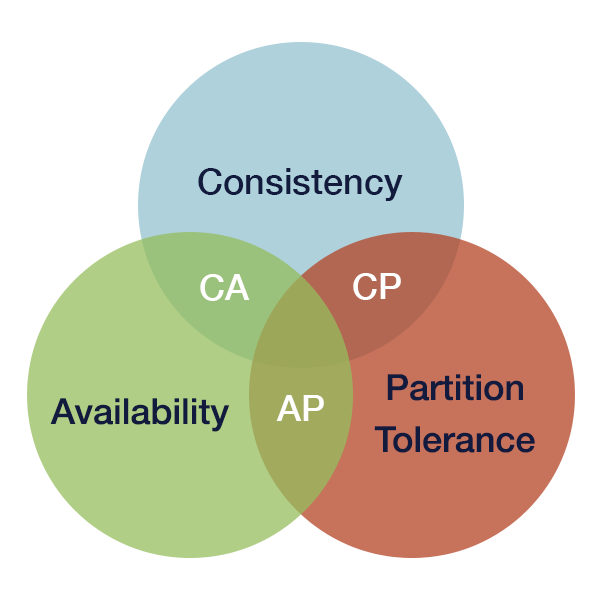
The CAP Theorem
Also known as Brewer’s theorem, this reasoning hypothesizes that distributed data stores cannot simultaneously offer more than one of these 3 guarantees, and a compromise must instead be met:
- Consistency, as explained above.
- Availability, so that resources are always available without an error response.
- Partition tolerance, i.e. removing the threat of single points or nodes of failure.
NoSQL Relies on the BASE Model
NoSQL is schema-free. It avoids single points of failure by replicating its data stores: Which allows it to scale better, handling massive volume data with near-infinite variety.
NoSQL keeps only the isolation aspect (e.g. as a set property requirement for specific fields) and throws out the A, C, and D obligations. It instead uses a softer design known in shorthand as BASE:
- Basically available — A guarantee for the availability of your data. Any request will generate a response, which can include failure.
- Soft state — Your system’s state is permitted to change throughout time.
- Eventual consistency — After its input ceases, your system eventually reaches consistency.
NoSQL Types Evolve Agilely
Let’s look at the four main categories of non-relational databases in order to demonstrate how this model is generally well-suited to agile devops. The four main types are key-value stores, wide column stores, graph databases, and document databases.
- Key value stores — Examples: Riak, Redis, and Voldemort. A high-performance ideal for storing session and comments data due to the fact that there is no default query language. Data is retrieved using put, delete, and get commands.
- Wide column stores — Examples: Cassandra and HBase. Outperforms RDBMS for metadata-based insight queries done in OLAP applications, such as business reporting, budgeting and forecasting, and even agriculture, as columnar databases easily access specific columns, and aggregate and surmise faster on wide-reaching portions of its database when there are no row-oriented restraints focused only on small-transaction sections of the database.
- Graph databases — Examples: Neo4J and HyperGraphDB. Especially popular with social networks due to its ability to run social network analyses based on the Six Degrees of Separation concept. Despite that, it’s used diversely for cross-sector industry collaborations. Graph databases represent the growing union between SQL and NoSQL: Rich querying of highly related data at a massive, flexible scale.
- Document databases — Examples: CouchDB and MongoDB. Data is semi-structured and stored as JSON, BSON, or XML documents. Each document is a record containing data without joins or relations support. There’s a wide range of use cases, including for headless CMS and blogging platform uses in web apps; management of memberships, challenges completed, and in-game stats for gaming; and as general repositories for user accounts, user-generated content, and logs/analytics.
When To Use NoSQL: Closing Thoughts
This guide is a basic place to begin exploring NoSQL. If you are interested in being an authority in this space, I would suggest thoroughly understanding the design landscape first.
Implementations that are available, whatever your problem domain, are evolving by the day. The non-relational model is an exciting development and is hybridizing so rapidly that today the most appropriate shorthand for “non-relational” models should be Not-Only-SQL.
Check out Butter CMS's API documentation to learn more about how an API-based Headless CMS can work with any tech stack to create fast and adaptable applications.
ButterCMS is the #1 rated Headless CMS












Related articles
Don’t miss a single post
Get our latest articles, stay updated!
Alex Williams is a seasoned full-stack developer and the owner of Hosting Data UK (https://hostingdata.co.uk/). After graduating from the University of London, majoring in IT, Alex worked as a developer leading various projects for clients from all over the world for almost 10 years. Alex recently became an independent IT consultant and started his own blog. There, he explores web development, data management, digital marketing, and solutions for online business owners just starting out.