
GSD
GraphQL vs REST API: A Quick Comparative Guide
Posted by Deven Joshi on October 19, 2023
If you have written code for any modern platform, you’ve almost certainly interacted with a web API, more often than not, that API was probably REST. If you’ve been programming for a long time or have used a slightly older system, that API may have even been SOAP.
But recently, there’s been quite a lot of chatter about GraphQL. Which leads us to the obvious questions: What is GraphQL? And how does it compare to the REST APIs that are used in most applications? The goal of this article is to help you answer these questions and understand the key differences between both approaches.
Table of contents
What is a REST API?
REST (REpresentational State Transfer) has been the go-to architecture for creating APIs on the modern internet. The REST architecture contains resources that can be accessed and manipulated via multiple kinds of calls to the API endpoints. The response can be in any format, but JSON (JavaScript Object Notation) is the standard adopted across the web, so returning data in other formats is rare. A “resource” is the basic object of REST and is identified by a URI (Uniform Resource Identifier). This resource can be actual structured data, a service, or anything that a user can access.
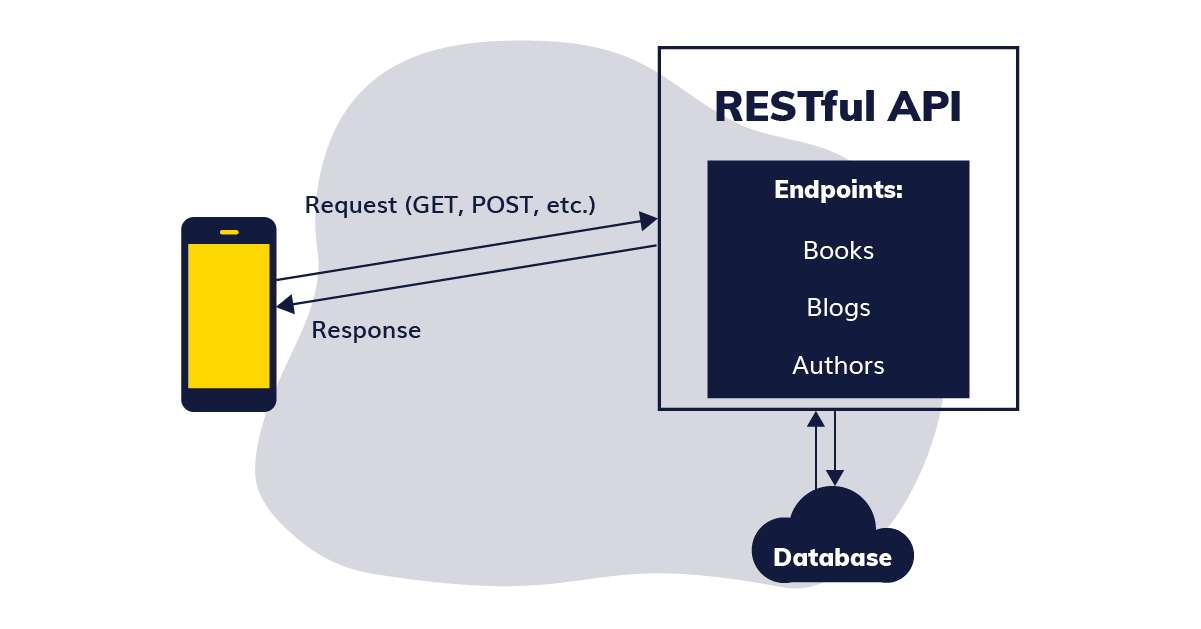
REST uses HTTP calls such as GET, POST, PUT, DELETE, etc. In most cases, any of the aforementioned HTTP calls to a REST API deal with the same kind/structure of data - fetching two different books using their IDs won’t have a large amount of variance in the data they provide, and submitting a new book will likely have a fixed format.
One thing to note is that a REST API is stateless - meaning there is no continuous connection with the server. All calls to the API are valid in isolation assuming they have the correct identification headers if any.
History
Before REST, SOAP (Simple Object Access Protocol) was used by the bulk of companies to create APIs. The motivations behind both were similar: to provide an easy exchange of data across platforms. While REST allows several data formats, SOAP works exclusively with XML.
An important point to note here is that SOAP is a protocol while REST is an architectural pattern. When we say “REST API,” we really mean “RESTful API,” which is the correct term for web services that follow the REST architecture.
In the early 2000s, a group led by Roy Fielding created the REST architecture with the goal of obtaining a better structure for data interchange. REST APIs effectively won out over SOAP APIs due to their higher compatibility, stateless architectures, and better caching mechanisms.

Basic workings of REST APIs
To better understand REST APIs, let’s take a look at an example of using one to create an app.
A great example of a REST API is ButterCMS itself. A while ago, I helped write the Dart language implementation for the ButterCMS API. When you explore the API in detail, you will find the different endpoints supplied by ButterCMS:
/// This file stores all constants required for querying API
const baseUrl = "api.buttercms.com";
const pagesEndpoint = "v2/pages";
const contentEndpoint = "v2/content";
const postsEndpoint = "v2/posts";
const authorsEndpoint = "v2/authors";
const categoriesEndpoint = "v2/categories";
const tagsEndpoint = "v2/tags";
const postSearchEndpoint = "v2/search";These endpoints are for the different kinds of data possible with ButterCMS and the general HTTP methods (GET, POST, etc). They help with multiple operations related to them. Therefore, the “pages” endpoint likely helps with all kinds of operations related to pages in Butter - creation, fetching, update, deletion, etc.
Note that the “v2” in the endpoints also marks the version of the API which you can use to upgrade the API and deprecate the earlier version without breaking any code using the API since the new version likely gives different data than the original. So when the API creator makes significant changes to the schema, they can simply ask the users to fetch from, say, ‘v2/books’ instead of simply ‘/books’, which allows the original implementation to stay and not break existing implementations of the API while allowing the users to migrate to the new version at their own leisure.
Let’s take an actual example of this: say we want to create a blog post using the Butter REST API.
For this, Butter has allocated the “posts” endpoint (since it is v2, “v2/posts”) and needs certain data to create a full blog post. It also specifies we use the “POST” HTTP call to submit a post.
Here is what a demo request looks like:
curl -X POST \
https://api.buttercms.com/v2/posts/ \
-H 'Authorization: Token your_write_api_token' \
-H 'Content-Type: application/json' \
-d '{
"author": {
"email": "your@author.com" // You can also lookup by author "slug"
},
"categories": ["Recipes", "Meals"],
"tags": ["Butter", "Sushi", "Really Good Recipes"],
"featured_image": "https://farm1.staticflickr.com/836/42903355654_8faa21171a_m_d.jpg",
"featured_image_alt": "Featured image alt text example.",
"slug": "this-is-a-blog-post",
"title": "This is a blog post",
"body": "<h1>Butter</h1><p>I am so hungry!</p>",
"summary": "This is a blog post summary.",
"seo_title": "This is a blog post",
"meta_description": "This is a blog post to test the API.",
"status": "published"
}'Let’s decode this line by line.
First, we specify that this is a POST request to the “v2/posts” endpoint.
Second, in the header, we provide a write token to prove we are authorized to create posts.
In the data given to the API, we specify everything the API asks us to specify for creating the post.
When this is submitted to the API, it will respond with the appropriate HTTP status code, which indicates if creation succeeded or failed.
Similarly, we can use the GET call for retrieving blog posts from the web:
curl -X GET
'https://api.buttercms.com/v2/posts/?page=1&page_size=10&exclude_body=false&author_slug=api-test&category_slug=test-category&tag_slug=test-tag&auth_token=your_api_token'This gives us a response of the blog posts within the query parameters we specified:
{
"meta": {
"count": 1,
"next_page": null,
"previous_page": null
},
"data": [
{
"url": "http://www.example.com/blog/this-is-a-blog-post",
"created": "2020-10-08T18:29:19.987936Z",
"updated": "2020-10-09T15:49:54.580309Z",
"published": "2020-10-08T18:08:00Z",
"author": {
"first_name": "API",
"last_name": "Test",
"email": "apitest@buttercms.com",
"slug": "api-test",
"bio": "This is my bio.",
"title": "API",
"linkedin_url": "https://www.linkedin.com/in/API",
"facebook_url": "https://www.facebook.com/API",
"twitter_handle": "buttercmsapi",
"profile_image": "https://buttercms.com/api.png"
},
"categories": [
{
"name": "test category",
"slug": "test-category"
}
],
"tags": [
{
"name": "test tag",
"slug": "test-tag"
}
],
"featured_image": null,
"featured_image_alt": "",
"slug": "this-is-a-blog-post",
"title": "This is a blog post",
"body": "<p class=\"\">This is a blog post to test the API.</p>",
"summary": "This is a blog post to test the API.",
"seo_title": "This is a blog post",
"meta_description": "This is a blog post to test the API.",
"status": "published"
}
]
}Notice that we can only specify what kind and how many blog posts we want — we cannot eliminate any data we do not need inside each blog post while retrieving them.
What is GraphQL?
GraphQL (Graph Query Language) was created by engineers at Facebook to solve issues they were facing while building the Facebook app with traditional RESTful APIs (detailed in the next section). Similar to the SOAP vs. REST comparison, while REST is simply an architecture, GraphQL adds a whole new query language and a different way of structuring the backend as well. While normal HTTP calls are also involved and data returned can be in multiple formats just like REST, the calls sent to the server have a distinct structure.
Unlike the separated structured data of REST, GraphQL contains interconnected data and objects with the vertices of the graph being the objects and the edges referring to the connections between them.
GraphQL also solves several other problems of the REST format, namely the over or under-fetching of data (discussed ahead). In the REST format, several calls are often needed to completely fetch the complete data, and it also retrieves ALL aspects of the object, not just the parts we want.
History
Originally, when developing the Facebook app, the company had bet largely on web technologies to build it. However, when the company finally decided to build a native mobile app, normal APIs could not provide an efficient way to build aspects of the app. As an example, the news feed experience, which took several kinds of data—the post itself, the people who liked, commented, shared, and much more—needed optimization. Since the posts were interconnected, a simple hierarchical structure of data was difficult to work with—which is why they needed to create a new way to structure and query data. GraphQL was originally developed at Facebook by Lee Byron and released to the public in 2015. It is now hosted by the Linux foundation. You can learn more about GraphQL’s history here and here.
Basic workings of GraphQL
GraphQL diverges from REST on both the backend and client-side. It was mentioned above that we can select the kinds of data we need from the API, and this needs to be specified in the request that we make to the API. On the backend, since there are no specific endpoints like in REST and there's just a generic endpoint, we need to specify what kinds of API calls may be made through this endpoint. In REST different types of data are fetched/posted via endpoints—like fetching a list of books from a ‘/books’ endpoint—there are no different endpoints in GraphQL: hence, a “generic” endpoint.
On the backend, it needs to be declared whether the API call is a query (data fetch) or a mutation (data update). These are the two types of requests we can make to the GraphQL endpoint.
query PlayerAndFriends {
player {
name
level
friends {
name
level
}
}
}Here, we create a query on the backend for the client-side to use.
Let’s consider a multiplayer online game. In the game, we would potentially need to know the name and friends of the current player. To request this, we would query the API something like this:
{
player {
name
friends {
name
}
}
} As you can see, we can specifically request the fields we need from the player: hence, no other unneeded data (ex. date of joining, last online, etc) is provided to the client side. The same is done for the linked friend objects: we can ask for specific objects in the friend objects.
Then there are mutations, which allow you to mutate (create/update/delete) data. On the API side, we declare this to create a new player which creates a possible mutation query with the appropriate parameters.
mutation CreatePlayer($name: Name!, $level: Level!) {
createPlayer(name: $name, level: $level) {
name
level
}
}When the user wants to create a player, they can call the API and supply data for the variables:
{
"name": "Master Chief",
"level": "9000",
}On the client side, the call is structured quite differently from a REST call. As an example, when fetching data, we can fetch multiple kinds of data and we can also specify the specific fields of the objects that we need, unlike in REST where we could only query specific kinds of objects but receive the full data (with all fields).
GraphQL vs. REST API: Side-by-side comparison
Now that we have seen examples of both REST and GraphQL in action, it would be appropriate to know how they compare across a few common factors.
Usability
Now, before we discuss usability, it is important to know that most REST APIs can be implemented slightly differently from others, and while this is a general comparison, some REST APIs may have higher usability than others. Since REST is an architecture, there may be some well-implemented APIs as well as more cluttered ones which do not specify appropriate endpoints and/or implement versioning badly.
In terms of data, GraphQL only gives the developer what they specify and nothing more, while REST gives them pretty much everything under the sun if it exists in the structured data requested from the endpoint. While this may make GraphQL easier to work with on the client-side since multiple calls aren’t often required to fetch the complete data, a major drawback to this is that more specification is required on the client when requesting data along with more setup required on the API side to handle all the required queries. This also requires some extra steps on the backend to specify the queries and mutations possible for the API itself, as well as the data possible to be requested from a potential query. Also, on the client-side, there is the extra work of specifying the required fields for every query.

There are also some other concerns in terms of usability: most RESTful API providers provide rate limits for each endpoint they have which guarantees that no API endpoint is called too often. They can also charge appropriately or provide certain plans which make it easy for the developer to get what they like. Since GraphQL has generic queries on the client-side, this is resolved on the backend and rate limits become harder to implement.
If the client needs generally separated data (a book list, a detailed view of an object, etc.), REST does quite well and is far easier to implement. When data is reasonably sized, pagination is implemented for large sets, and several calls aren’t required to fetch data, taking the REST approach can save time and money in development for a company.
If the client-side implementation contains several interconnected elements that may require a lot of REST calls, GraphQL would likely be a good option and worth the time implementing since it would be more efficient over time.
Performance
The main factors that go into deciding if REST or GraphQL gives better performance are the types of data fetched and how often they need to be fetched.
Since GraphQL only provides the data required (possibly fetching from multiple types of data), it can provide less data and take less time to complete the call since it needs to supply only the required data.
REST, on the other hand, may take more time—not because API calls themselves are inherently slower, but because multiple calls may need to be executed in order to fully complete an operation on the client-side as well as provide the full set of data without regard for what the user requested. If two different types of objects are required to be fetched, two different REST calls will be involved, leading to increased fetch times.
Where REST holds the upper hand, however, is when repeated calls are requested. It can use HTTP caching mechanisms to speed up API calls and no extra processing is required. This is unlike GraphQL, which may potentially need more tooling to do so since all GraphQL queries are POST queries to the main GraphQL endpoint
Security
As discussed earlier, REST APIs split operations into different endpoints and all calls do not run through a single node. This makes it easier to detect and shut down Distributed Denial of Service (DDoS) attacks. Since GraphQL uses generic queries which effectively go through a single endpoint, this is harder to do.

Limiting mechanisms like quotas and rate limits are used to avoid overuse and, more importantly, limit the frequency of calls made to the API to make sure nothing is overwhelmed, which can happen in the event of a malicious attack. REST allows a relatively easy implementation of rate limits as well as an easily defined split of the types of data that can be requested. This also allows individual rate limits for API endpoints which can be moderated by the API provider based on a plan or traffic conditions on the API itself.
Authentication mechanisms are generally simpler to implement on REST than on GraphQL. GraphQL users may have to do additional work in relation to authorization compared to REST, which is quite critical to the working of an API. This will likely change over time. But for now, REST is simply the more mature framework to handle authentication.
Caching
REST APIs support caching using in-built HTTP mechanisms whereas GraphQL does not. GET and POST requests can be cached in REST, GET requests can be cached by default, whereas POST requests may be made cacheable after some configuration. Since GET requests may supply significant amounts of data or perhaps be called a large number of times, caching them makes end applications run a lot faster and reduces the load on the API.
This enables REST to reduce response times when repeatedly requesting the same kinds of data. However, it can be argued that since GraphQL can reduce unnecessary data in the requests themselves, this isn’t as bad as it can potentially be. You can find more info about REST API caching in REST API Tutorial's article here.
GraphQL cannot use the HTTP methods to cache info since it uses a generic POST method to use the API. However, there are certain tools like Apollo which can make caching easier in GraphQL, as well.
Analytics
API providers need a good idea about the frequency of usage of various kinds of data for caching and optimization, as well as for things like their sales and marketing strategies. Since the API endpoints for REST APIs are clearly separated, even basic tracking by URI can give significant results. Additionally, a lot more tooling exists for more in-depth analysis since REST has been around for a far longer time.
On the flip side, since the client-side can specify the data it requires, the backend can identify what the requirements of the users are in much more detail since the connections between the data become more apparent. Tooling for GraphQL is generally more sparse, although it is not nonexistent.
The Verdict
GraphQL has generated a large amount of excitement in the developer community, so one can assume that it does solve some genuine problems that plague traditional RESTful APIs, and ten years down the line it may even be the standard for writing new APIs on the web—or perhaps not. The reality of the situation is that GraphQL is still relatively new to the game and only time will tell if it really matches all the advantages and convenience that REST provides. REST is still the undeniably more mature option when it comes to tooling, analytics, caching, and overall developer familiarity. So what should you do?
Personally, I think the best thing to do is evaluate whether a RESTful API fits well within the end product you intend to create or if it might be beneficial for you to try GraphQL. Furthermore, everyone should try both at least once. This way even if one ends up not working for you, you'll gain a more well-rounded perspective when thinking about APIs.
ButterCMS is the #1 rated Headless CMS












Related articles
Don’t miss a single post
Get our latest articles, stay updated!
Deven is a developer, speaker and technical writer for Flutter and Android. He is an AAD graduate and enjoys playing chess in his spare time. His writing interests range from widget deep-dives and plugin integrations to app-recreations and general analysis. Follow his work at medium.com/@dev.n.